Warning: package 'tidyr' was built under R version 4.3.3
library(here) #For reading in data from absolute path
here() starts at C:/Users/Client/Documents/antonioflores-P2-portfolio
library(dplyr)# For Piping data
Warning: package 'dplyr' was built under R version 4.3.3
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(ggplot2) # EDA Charts/Graphs
Warning: package 'ggplot2' was built under R version 4.3.3
#Reading in the Datadatalocation =here("cdcdata-exercise", "data", "Center_for_Medicare___Medicaid_Services__CMS____Medicare_Claims_data_20240701.csv")data =read.csv(datalocation)
The dataset comes from the CDC’s data repository and can be accessed with this link. Options exist for exporting via CSV or through the use of an API.
The Center for Medicare & Medicaid Services (CMS) gathers large amounts of health data from Medicare/Medicaid patients. From this data source, indicators have been computed by the CDC’s Division of Heart Disease and Stroke Prevention (DHDSP), and that is the dataset that will be used for this activity.
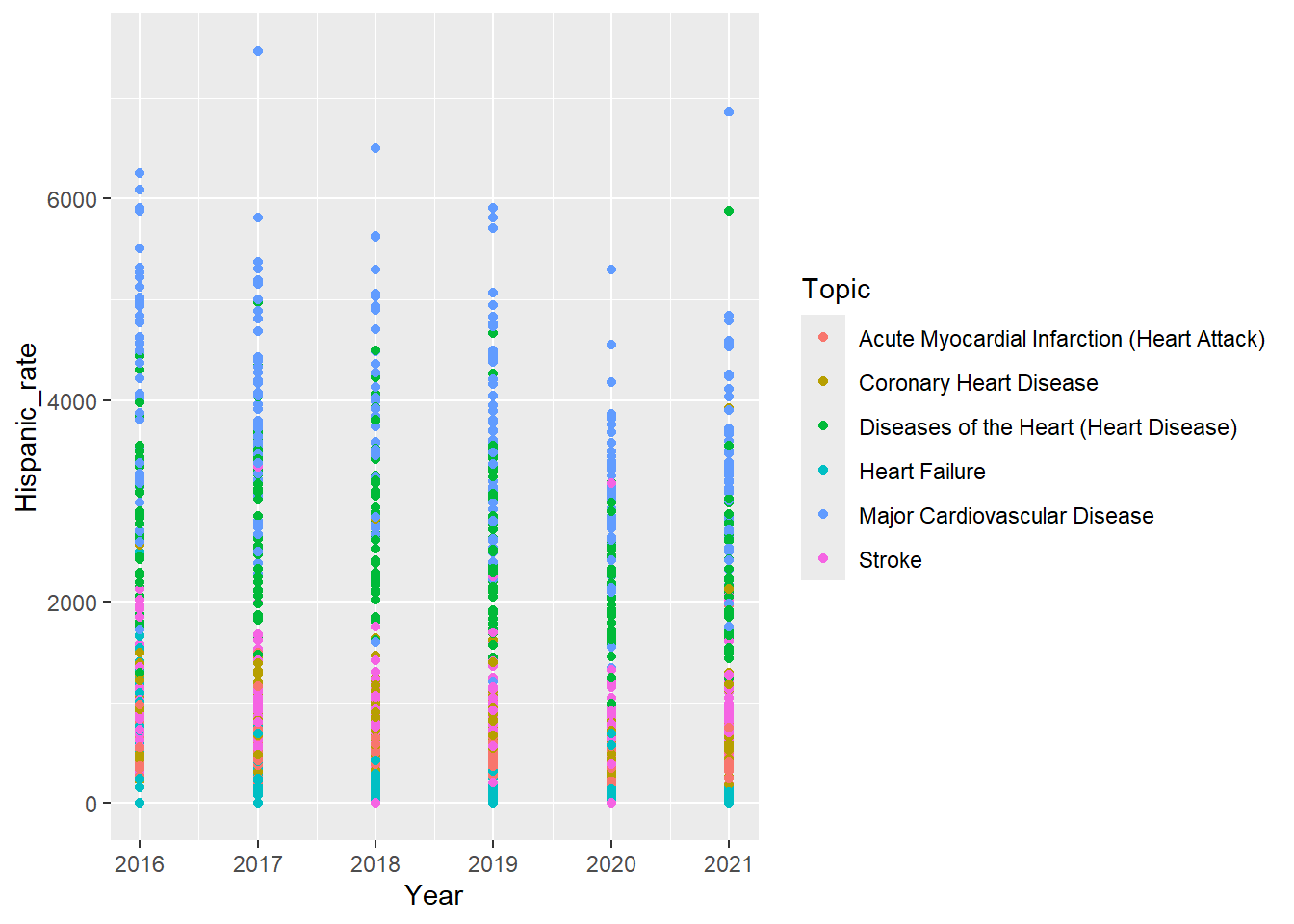
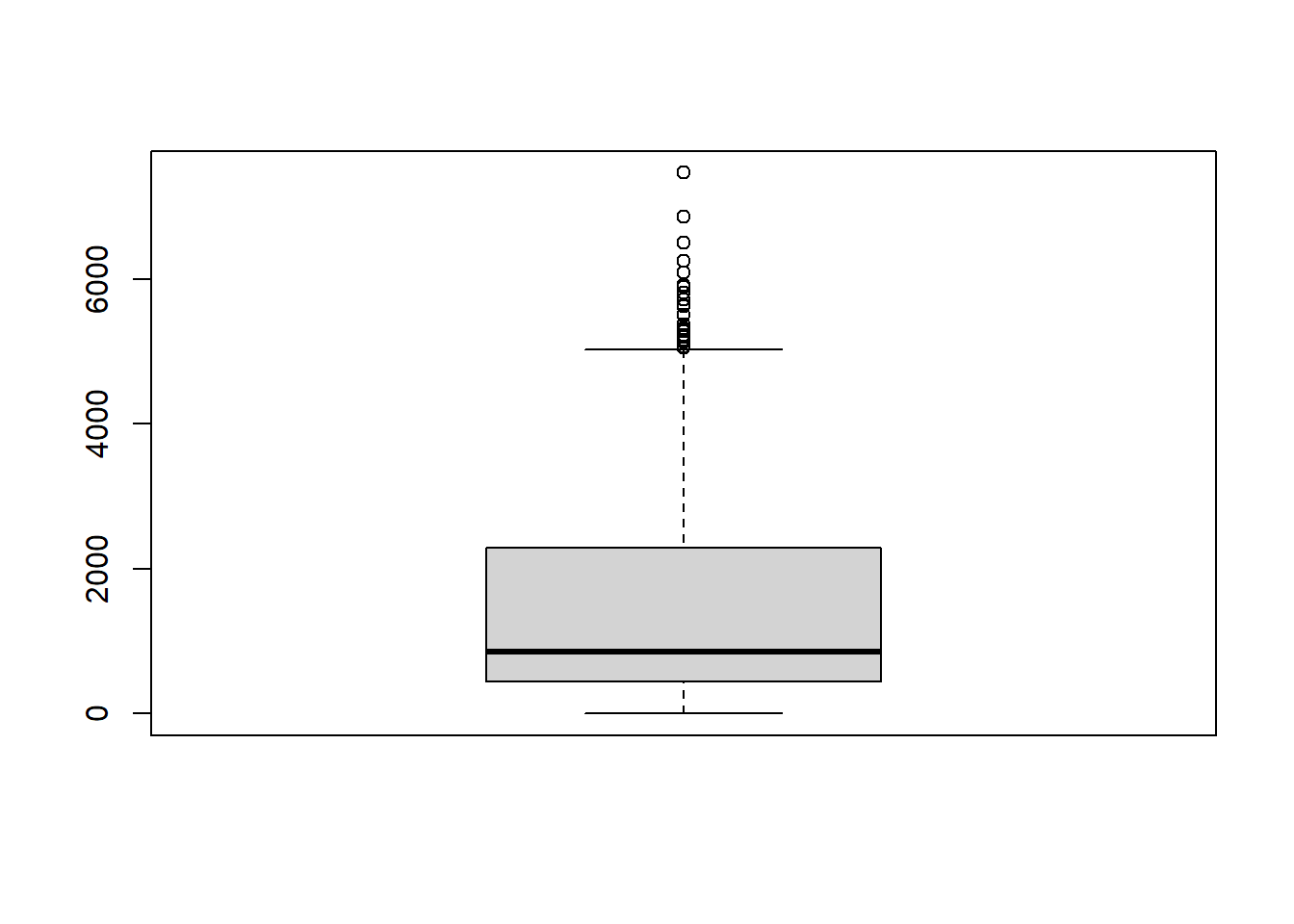
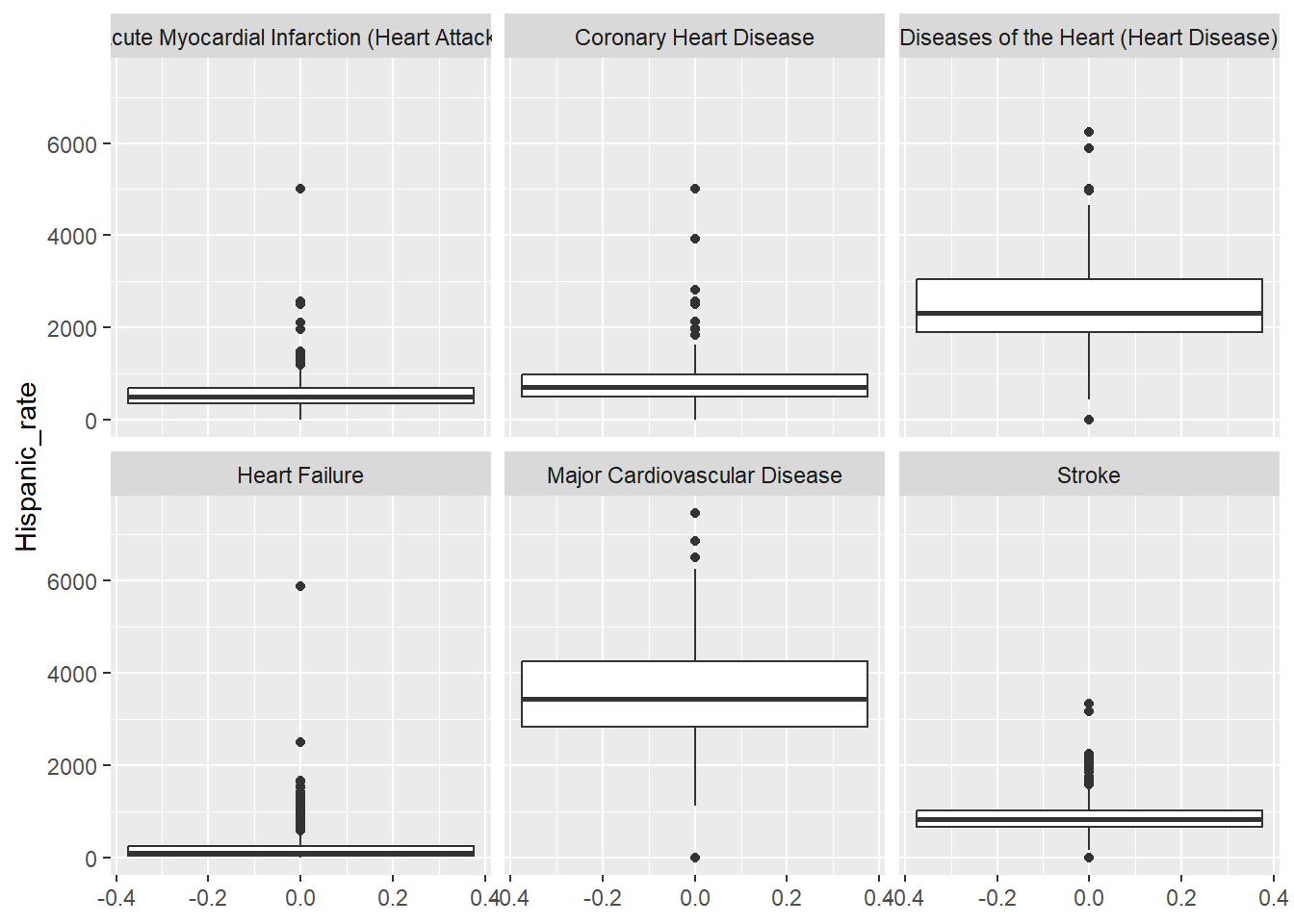
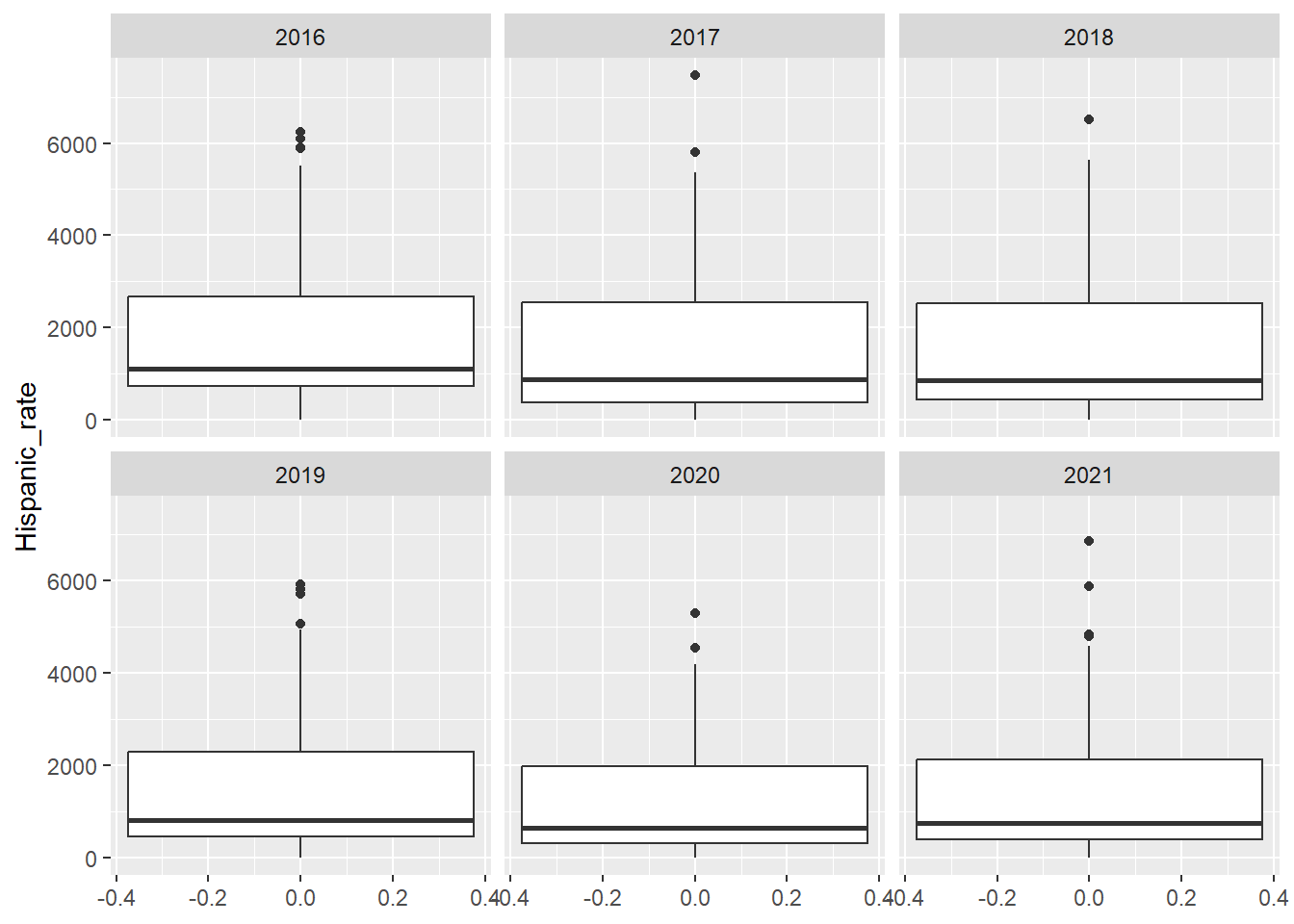
Before Cleaning: Each row contains a single data value for a particular category of a demographic (which is one of Race, Gender, Age) for each topic (Heart Failure, Stroke, etc), for each state, for each year(2016-2021).
In other words, for each year, there is a row for each state, for each state there is a row for each topic (5), for every topic there is a row for either percentage or rate, for each of these rows, there is a row for either gender, age, or race, and for each demographic there is one row per option (Male, Female, over75, etc.)
str(data)
'data.frame': 33454 obs. of 30 variables:
$ RowId : logi NA NA NA NA NA NA ...
$ YearStart : int 2016 2017 2018 2019 2020 2021 2017 2021 2019 2018 ...
$ LocationAbbr : chr "US" "US" "US" "US" ...
$ LocationDesc : chr "United States" "United States" "United States" "United States" ...
$ DataSource : chr "Medicare" "Medicare" "Medicare" "Medicare" ...
$ PriorityArea1 : chr "None" "None" "None" "None" ...
$ PriorityArea2 : logi NA NA NA NA NA NA ...
$ PriorityArea3 : chr "None" "None" "None" "None" ...
$ PriorityArea4 : logi NA NA NA NA NA NA ...
$ Class : chr "Cardiovascular Diseases" "Cardiovascular Diseases" "Cardiovascular Diseases" "Cardiovascular Diseases" ...
$ Topic : chr "Major Cardiovascular Disease" "Major Cardiovascular Disease" "Major Cardiovascular Disease" "Major Cardiovascular Disease" ...
$ Question : chr "Major cardiovascular disease hospitalization rate among Medicare Fee-For-Service beneficiaries (65+); CMS Medicare" "Major cardiovascular disease hospitalization rate among Medicare Fee-For-Service beneficiaries (65+); CMS Medicare" "Major cardiovascular disease hospitalization rate among Medicare Fee-For-Service beneficiaries (65+); CMS Medicare" "Major cardiovascular disease hospitalization rate among Medicare Fee-For-Service beneficiaries (65+); CMS Medicare" ...
$ Data_Value_Type : chr "Crude" "Crude" "Crude" "Crude" ...
$ Data_Value_Unit : chr "Rate per 100,000" "Rate per 100,000" "Rate per 100,000" "Rate per 100,000" ...
$ Data_Value : num 2368 2404 2482 5395 4505 ...
$ Data_Value_Alt : num 2368 2404 2482 5395 4505 ...
$ Data_Value_Footnote_Symbol: logi NA NA NA NA NA NA ...
$ Data_Value_Footnote : logi NA NA NA NA NA NA ...
$ Low_Confidence_Limit : num 2318 2358 2439 5382 4493 ...
$ High_Confidence_Limit : num 2418 2450 2526 5408 4518 ...
$ Break_Out_Category : chr "Race" "Race" "Race" "Gender" ...
$ Break_Out : chr "Unknown" "Unknown" "Unknown" "Male" ...
$ ClassId : chr "C1" "C1" "C1" "C1" ...
$ TopicId : chr "T1" "T1" "T1" "T1" ...
$ QuestionId : chr "MD101" "MD101" "MD101" "MD101" ...
$ Data_Value_TypeID : chr "Crude" "Crude" "Crude" "Crude" ...
$ BreakOutCategoryId : chr "BOC04" "BOC04" "BOC04" "BOC02" ...
$ BreakOutId : chr "RAC08" "RAC08" "RAC08" "GEN01" ...
$ LocationId : int 59 59 59 59 59 59 59 59 30 59 ...
$ GeoLocation : chr "" "" "" "" ...
summary(data)
RowId YearStart LocationAbbr LocationDesc
Mode:logical Min. :2016 Length:33454 Length:33454
NA's:33454 1st Qu.:2017 Class :character Class :character
Median :2018 Mode :character Mode :character
Mean :2018
3rd Qu.:2020
Max. :2021
DataSource PriorityArea1 PriorityArea2 PriorityArea3
Length:33454 Length:33454 Mode:logical Length:33454
Class :character Class :character NA's:33454 Class :character
Mode :character Mode :character Mode :character
PriorityArea4 Class Topic Question
Mode:logical Length:33454 Length:33454 Length:33454
NA's:33454 Class :character Class :character Class :character
Mode :character Mode :character Mode :character
Data_Value_Type Data_Value_Unit Data_Value Data_Value_Alt
Length:33454 Length:33454 Min. : 0.0 Min. : 0.0
Class :character Class :character 1st Qu.: 5.1 1st Qu.: 5.1
Mode :character Mode :character Median : 25.0 Median : 25.0
Mean : 845.1 Mean : 845.1
3rd Qu.: 965.5 3rd Qu.: 965.5
Max. :8118.2 Max. :8118.2
Data_Value_Footnote_Symbol Data_Value_Footnote Low_Confidence_Limit
Mode:logical Mode:logical Min. : -1.0
NA's:33454 NA's:33454 1st Qu.: 3.5
Median : 8.3
Mean : 742.4
3rd Qu.: 825.9
Max. :7925.8
High_Confidence_Limit Break_Out_Category Break_Out ClassId
Min. : -1.0 Length:33454 Length:33454 Length:33454
1st Qu.: 7.2 Class :character Class :character Class :character
Median : 92.5 Mode :character Mode :character Mode :character
Mean : 1027.8
3rd Qu.: 1212.2
Max. :18238.6
TopicId QuestionId Data_Value_TypeID BreakOutCategoryId
Length:33454 Length:33454 Length:33454 Length:33454
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
BreakOutId LocationId GeoLocation
Length:33454 Min. : 1.00 Length:33454
Class :character 1st Qu.:17.00 Class :character
Mode :character Median :29.00 Mode :character
Mean :29.56
3rd Qu.:44.00
Max. :59.00
head(data)
RowId YearStart LocationAbbr LocationDesc DataSource PriorityArea1
1 NA 2016 US United States Medicare None
2 NA 2017 US United States Medicare None
3 NA 2018 US United States Medicare None
4 NA 2019 US United States Medicare None
5 NA 2020 US United States Medicare None
6 NA 2021 US United States Medicare None
PriorityArea2 PriorityArea3 PriorityArea4 Class
1 NA None NA Cardiovascular Diseases
2 NA None NA Cardiovascular Diseases
3 NA None NA Cardiovascular Diseases
4 NA None NA Cardiovascular Diseases
5 NA None NA Cardiovascular Diseases
6 NA None NA Cardiovascular Diseases
Topic
1 Major Cardiovascular Disease
2 Major Cardiovascular Disease
3 Major Cardiovascular Disease
4 Major Cardiovascular Disease
5 Major Cardiovascular Disease
6 Major Cardiovascular Disease
Question
1 Major cardiovascular disease hospitalization rate among Medicare Fee-For-Service beneficiaries (65+); CMS Medicare
2 Major cardiovascular disease hospitalization rate among Medicare Fee-For-Service beneficiaries (65+); CMS Medicare
3 Major cardiovascular disease hospitalization rate among Medicare Fee-For-Service beneficiaries (65+); CMS Medicare
4 Major cardiovascular disease hospitalization rate among Medicare Fee-For-Service beneficiaries (65+); CMS Medicare
5 Major cardiovascular disease hospitalization rate among Medicare Fee-For-Service beneficiaries (65+); CMS Medicare
6 Major cardiovascular disease hospitalization rate among Medicare Fee-For-Service beneficiaries (65+); CMS Medicare
Data_Value_Type Data_Value_Unit Data_Value Data_Value_Alt
1 Crude Rate per 100,000 2367.6 2367.6
2 Crude Rate per 100,000 2403.7 2403.7
3 Crude Rate per 100,000 2482.3 2482.3
4 Crude Rate per 100,000 5395.0 5395.0
5 Crude Rate per 100,000 4505.4 4505.4
6 Crude Rate per 100,000 4694.6 4694.6
Data_Value_Footnote_Symbol Data_Value_Footnote Low_Confidence_Limit
1 NA NA 2318.3
2 NA NA 2358.1
3 NA NA 2438.9
4 NA NA 5381.7
5 NA NA 4493.3
6 NA NA 4682.0
High_Confidence_Limit Break_Out_Category Break_Out ClassId TopicId QuestionId
1 2417.9 Race Unknown C1 T1 MD101
2 2450.2 Race Unknown C1 T1 MD101
3 2526.4 Race Unknown C1 T1 MD101
4 5408.2 Gender Male C1 T1 MD101
5 4517.5 Gender Male C1 T1 MD101
6 4707.2 Gender Male C1 T1 MD101
Data_Value_TypeID BreakOutCategoryId BreakOutId LocationId GeoLocation
1 Crude BOC04 RAC08 59
2 Crude BOC04 RAC08 59
3 Crude BOC04 RAC08 59
4 Crude BOC02 GEN01 59
5 Crude BOC02 GEN01 59
6 Crude BOC02 GEN01 59
Data Cleaning
First, we’re just changing some fields that were mislabeled (e.g., Arizona Abbreviation was AR), converting categorical variables to factors, and removing useless columns)